MetalLB with Calico BGP: Deployment, Architecture, and Validation
Deploy MetalLB as controller-only and let Calico’s BGP advertise a LoadBalancer pool. The guide covers Helm setup, IP pool config with avoidBuggyIPs, route flow analysis, source-IP-preserving Local policy, and failover tests for production-grade bare-metal LB.


Motivation and Background
In bare-metal Kubernetes clusters, the LoadBalancer service type requires custom solutions since no cloud provider is managing external load balancers. MetalLB is a widely-used add-on that provides LoadBalancer functionality for on-premises Kubernetes clusters. MetalLB traditionally operates in two modes: Layer 2 (L2) mode and Layer 3 (BGP) mode. When using Calico as the CNI plugin with BGP routing, MetalLB should operate in L2 mode to handle IP allocation via ARP, while Calico manages BGP routing for LoadBalancer IPs. This design ensures there are no conflicts between MetalLB and Calico’s BGP sessions.

Addressing the Challenge with Calico's Integration with MetalLB
In this configuration, MetalLB operates in L2 mode, responsible for allocating IP addresses to Kubernetes LoadBalancer services and using ARP to announce these IPs to the network. Calico manages the BGP routing, advertising the service IPs (including those assigned by MetalLB) to the upstream routers, ensuring that traffic to these IPs is routed correctly. By having MetalLB in L2 mode and Calico handle BGP, we can ensure proper routing of service IPs without conflicts and maintain efficient IP allocation and network traffic flow.
Architecture Overview and Component Roles
MetalLB (Controller-Only Mode): MetalLB operates in L2 mode and is responsible for allocating IP addresses from a pre-defined pool to Kubernetes LoadBalancer services. In this mode, MetalLB uses ARP (Address Resolution Protocol) to advertise the service IPs to the network. MetalLB listens for ARP requests for these IPs and responds with the MAC address of the node hosting the corresponding service. This ensures that external traffic can reach the Kubernetes services.
Calico (BGP Routing): Calico is the CNI plugin, providing both pod networking and BGP capabilities. Each Kubernetes node running Calico establishes a BGP session with the ToR routers, advertising pod IPs and the LoadBalancer IP range to the upstream routers. Calico is responsible for advertising the LoadBalancer IPs and the service IP ranges over BGP, ensuring external traffic is properly routed to the nodes. Calico also adheres to Kubernetes' externalTrafficPolicy rules, ensuring traffic is routed to the correct nodes while preserving the client’s source IP.
Upstream Routers/Switches: The ToR routers or switches peer with Calico using BGP. These routers learn the LoadBalancer IP routes via BGP and propagate them to the external network. The routers forward traffic destined for the LoadBalancer IPs to the appropriate Kubernetes nodes that are hosting the service pods.
Kube-Proxy and Service Handling: Kube-proxy is responsible for implementing service IPs and routing traffic to the appropriate pods within the Kubernetes cluster. In the case of LoadBalancer services, kube-proxy uses NodePorts to forward traffic to pods. With externalTrafficPolicy: Cluster, kube-proxy forwards traffic to any node that advertises the LoadBalancer IP and hosts a pod for the service. This setup ensures that external traffic is efficiently distributed across nodes, with Calico handling the BGP announcements.

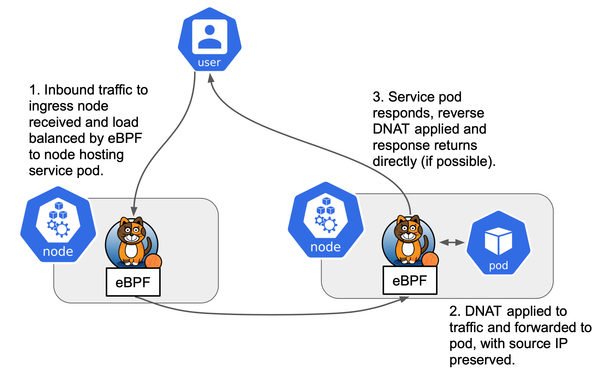
Flow of Traffic
In the case of L2 mode and Calico BGP, the traffic flow is as follows:
- A client sends traffic to the service's external IP.
- The upstream router, having learned the route via BGP from Calico, forwards the packet to a node in the Kubernetes cluster that is advertising the service IP.
- The node's kube-proxy forwards the traffic to the local pod, which responds back to the client.
- Calico ensures the proper routing of traffic from external clients to the correct node, and MetalLB handles ARP to ensure the IP is resolved to the correct node.
If a node failure occurs or a pod is rescheduled, Calico’s BGP routing ensures that the route to the service IP is updated quickly. Calico withdraws the route for the failed node and advertises the route for the new node hosting the pod, ensuring high availability.
Deployment Steps and Configuration
Deploying this setup involves configuring MetalLB via Helm, defining the IP address pool CRD, and adjusting Calico’s BGP settings. The following steps outline the process:
Install MetalLB in L2 Mode (ARP)
Install MetalLB in L2 mode using the Helm chart or manifests, ensuring that the speaker is enabled to handle ARP-based IP advertisement.
controller:
enabled: true # ensure the controller is deployed
speaker:
enabled: true # Enable the speaker for ARP-based IP announcements
# Calico will be responsible for BGP announcement
frr:
enabled: falseConfigure an IPAddressPool for the LoadBalancer IPs
Define the IP pool from which MetalLB will allocate LoadBalancer IPs. Ensure that MetalLB avoids IPs like .0 and .255 to prevent conflicts with network and broadcast addresses.
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: lb-pool-10-208-1
namespace: metallb-system
spec:
addresses:
- 10.208.1.0/24
avoidBuggyIPs: true # Skip .0 and .255 addresses
The avoidBuggyIPs: true flag ensures MetalLB will skip any address ending in .0 or .255 when assigning IPs. Alternatively, we could specify the address range as 10.208.1.1-10.208.1.254 to exclude them. No BGPAdvertisement resource is provided – leaving it out indicates that MetalLB itself will not advertise these routes (Calico will do it). If you were using MetalLB’s own BGP speaker, you would normally create a BGPAdvertisement CR to define how to announce the pool; here it’s deliberately omitted.
Apply this manifest to the cluster. Once created, MetalLB’s controller will be aware of the pool and ready to allocate addresses from it. (Note: ensure the MetalLB CRDs are installed by the Helm chart and that the controller is running before applying CRs.)

Enable BGP Route Advertisement in Calico for the Service Pool
Configure Calico to advertise the LoadBalancer IP range. This is done by updating the BGPConfiguration resource to include the LoadBalancer IP range:
calicoctl patch BGPConfiguration default --patch '{
"spec": {
"serviceLoadBalancerIPs": [ { "cidr": "10.208.1.0/24" } ]
}
}'
Service Exposure
Expose services using the LoadBalancer type and set externalTrafficPolicy: Cluster to ensure proper service exposure and IP advertisement.
apiVersion: v1
kind: Service
metadata:
name: web-server
namespace: demo
spec:
type: LoadBalancer
externalTrafficPolicy: Cluster
selector:
app: web-server
ports:
- port: 80
targetPort: 8080
protocol: TCP
Traffic Flow Verification
Once a LoadBalancer service is deployed and assigned an IP, it’s crucial to verify that everything works as expected. We will walk through several validation steps:
BGP Route Advertisement
First, confirm that the service IP (or its containing prefix) is being advertised via BGP by the Calico agents. On each node, you can check the BGP session status using Calico’s tools. For example, run calicoctl node status – this will show the BGP peers and the routes being advertised/received. You should see that the 10.208.1.0/24 network is in the list of exported routes. If the service is using externalTrafficPolicy: Local, check that each node with a service pod is advertising either the /24 or a /32 for the service IP. Another approach is to inspect the routing table on the ToR router: you should find an entry for 10.208.1.0/24 (or 10.208.1.5/32, etc.) pointing towards the Kubernetes node(s) via BGP. For instance, using a command like show ip route 10.208.1.0/24 on the router might reveal multiple next-hops (each node’s IP) if multiple nodes are advertising it. This confirms that Calico is advertising the LoadBalancer IP pool as configured. (If this route is missing, see the Troubleshooting section.)
External Connectivity Test
Next, test that an external client can reach the service. Using a machine outside the cluster (but within the network that the ToR serves), try to connect to the service IP. For example, if it’s a web service, run curl http://10.208.1.5/ (replace with your service’s IP and port as appropriate). The request should be routed to one of the Kubernetes nodes and then to the pod, and you should get a response. Success here indicates that the BGP advertisement and routing are correctly directing traffic into the cluster. If the connection fails, one thing to check is any firewall rules: ensure that the upstream network and the node itself allow traffic on the service’s port. Remember that, under the hood, the traffic is hitting the node on the NodePort (which is usually a high port). Kubernetes takes care of opening the NodePort on 0.0.0.0, but if the host has firewall (iptables rules or cloud security groups), they must permit the traffic. In most bare-metal setups with Calico, Calico’s own network policy could also block traffic if not allowed – ensure no network policy is inadvertently denying the external traffic.
Source IP Preservation
To verify that the client’s source IP is preserved (one of the key benefits of using Local mode), you can inspect the traffic reaching the pod. One simple method is to check the logs of the application pod if it logs client connections. For example, if the pod runs an Nginx or Apache, the access logs should show the real IP of the client (e.g., 10.0.0.25) rather than an internal node IP. If you don’t have such logging, you can deploy a test server that outputs the client address (for instance, a small Python/Go web server that prints the X-Forwarded-For or the remote address). You could also exec into the pod and use tools like tcpdump or ss to observe the source addresses of incoming connections.
Expected result: the source IP should match the external client’s IP. If you see the node’s IP instead, then likely the service is falling back to Cluster mode or traffic is being rerouted – recheck that externalTrafficPolicy is set to Local on the service, and that the pod indeed runs on the node that received the traffic. The Kubernetes docs note that externalTrafficPolicy=Local will preserve client IP and drop packets on nodes without endpoints, so each successful connection’s source IP preservation indicates traffic hit a node with a pod (as designed).
Node Failover Scenario
One of the advantages of using BGP for service routing is robust failover. We should test what happens if the node serving the LoadBalancer traffic goes down or the pod is rescheduled to a different node. To simulate this, perform a controlled failover test:
- Pod relocation: Cordone the node that is currently receiving traffic (
kubectl cordon <node>), then delete the pod (so it gets rescheduled on another node). Once the pod starts on a new node, Calico should detect that the new node now has an endpoint for the service and the old node does not. Calico on the old node will withdraw the BGP route for the service IP, and Calico on the new node will announce it. This transition is usually very fast (within seconds). Verify by checking routes on the router – the next-hop for 10.208.1.5 should update to the new node’s IP, or an additional route for the /32 from the new node appears while the old one disappears. Now try accessing the service IP again from the client. It should still work, now being served by the pod on the new node. In ideal cases, this failover happens with minimal disruption (a few dropped packets during convergence). - Node down: For a more drastic test, simulate a node failure (if possible in a staging environment). This could be shutting down the node or stopping the Calico BGP service on that node. The upstream router’s BGP session with that node will go down, and it will remove the route to 10.208.1.5 via that node. If Kubernetes reschedules the pod to another node, that node’s Calico will announce the route. If there was already a second pod on another node, traffic would fail over to that node’s route automatically. This kind of high availability is a strong feature of BGP-based load balancing – it avoids having a single choke point. After node failover, confirm that the service remains reachable and that the client IP is still preserved.
Throughout these tests, also keep an eye on the MetalLB controller’s logs (to see IP assignment events or errors) and Calico’s logs (for any BGP session issues or route advertisement logs). Both MetalLB and Calico provide metrics and diagnostics (MetalLB has metrics for allocated IPs; Calico’s calico-node status can show route counts, etc.) that can aid in verifying that everything is functioning.
Troubleshooting Common Issues
Even with the correct setup, a few issues can arise. Here are common problems and how to address them:
- MetalLB assigned an IP ending in .0 or .255: If you notice a service got the .0 or .255 address (e.g., 10.208.1.0 or 10.208.1.255 in our pool), it could lead to connectivity problems. Many networks consider the .0 and .255 of a /24 as network and broadcast addresses respectively, and some routers or clients will refuse to route them due to “smurf” attack protections. To avoid this, always set
avoidBuggyIPs: truein the IPAddressPool (or explicitly exclude those addresses). If one of those addresses was already allocated, you should remove that IP from the service. MetalLB won’t automatically reassign a new IP if the pool changes for an existing service; you might need to delete and recreate the service (or cycle the MetalLB controller) to force a new allocation. In summary, prevention is best: configure the pool to skip .0/.255 from the start. - No route to the LoadBalancer IP (service not reachable): If external clients cannot reach the service at all, and pinging the service IP yields no response, it’s likely that the BGP advertisement isn’t working. Check the Calico BGP configuration to ensure the
serviceLoadBalancerIPsfield includes the correct CIDR. A common oversight is forgetting to configure this, meaning Calico is not announcing the service range. If using Calico’s Kubernetes operator, ensure that the corresponding setting is enabled (in some Calico installations, this can be set via theadvertiseServiceLoadBalancerIPsin the FelixConfiguration or BGPConfiguration). Also verify that the BGP peering between the nodes and the router is established (usingcalicoctl node statusor looking at router BGP status). If the BGP session is down, obviously no routes will be advertised. Another possibility is that the MetalLB controller did not allocate an IP (service still inpendingstate for external IP). In that case, ensure the MetalLB controller is running and the IPAddressPool is correctly created (checkkubectl get ipaddresspool -A). Any errors in MetalLB’s controller logs (e.g., if the pool is misconfigured or no available IP) should be resolved. Once the BGP route is in place, the service IP should start responding. You can test route propagation by attempting a traceroute or checking the router’s routing table for the service IP. - Connectivity works but is intermittent or one node is blackholing traffic: This can happen if a node with no endpoints is somehow still advertising the service or receiving traffic. In theory, Calico’s per-node advertisement for Local services should prevent this. However, if all nodes advertise a broad /24 and the upstream router does ECMP, it might sometimes send traffic to a node without an endpoint. Those packets would be dropped by kube-proxy (as design), but from the client perspective it appears as intermittent packet loss. To mitigate this, ensure that Calico is actually doing per-service /32 advertisements. You might need to upgrade Calico if using an older version where this was not functioning correctly (earlier Calico 3.18+ should support it, but a bug or misconfiguration could cause advertisement of only the aggregate). If necessary, as a workaround, you could restrict the MetalLB IP pool to only specific nodes (using MetalLB’s
addressPool.spec.serviceSelectorsor scheduling all service pods to all nodes). Another angle is to check that the kube-proxy health check node port is functioning – some external load balancers use it to determine node readiness. Although we rely on BGP here, if using a cloud provider’s mechanism for health checking in tandem, ensure nodes without endpoints fail the health check so traffic isn’t sent to them. In pure BGP, this should be automatic via route withdrawal. - BGP session or route flapping causing connection drops: If you observe that connections drop periodically or fail over too often, it might be due to BGP stability. Check the BGP timers (hold time, keepalive) in Calico’s configuration – the default hold timer might be 180s which is quite long for failover. However, Calico might be using a shorter graceful restart timer when withdrawing service routes. Tune BGP timers if needed to achieve faster failover, but beware of too aggressive settings causing flaps. Also verify that BGP multipath is enabled on the upstream router. Without multipath, the router will only use one node as the next-hop for the /24, and if that node goes down, it has to converge to another, causing a brief outage. With multipath, it can load balance and instantly switch paths if one fails. On Cisco/FRR, this usually means enabling
maximum-pathsfor BGP. - Firewall and security issues: In some cases, everything on the Kubernetes side is correct, but network policies or host firewalls block the traffic. Calico’s default is to allow all traffic if no network policy is in place (policy is “deny” only if configured so). Ensure no NetworkPolicy is denying the external ingress. On the host, if running something like firewalld or iptables rules outside of kube-proxy, make sure traffic to the nodePort or BGP ports isn’t blocked. Calico BGP uses TCP port 179; if that was firewalled, the BGP session wouldn’t come up. The service traffic will come to nodePort (30000-32767 range by default), which should be allowed. If using
externalTrafficPolicy: Local, Kubernetes by default opens the healthCheckNodePort on each node; if you have an upstream load balancer performing health checks (not in pure BGP scenario), ensure those can reach that port. Although our scenario doesn’t use an external load balancer, healthCheckNodePort is still allocated (visible inkubectl get svc -o yamloutput) and kube-proxy will respond with 200 OK on that port on nodes with endpoints. This is primarily for cloud LBs; for us, it’s not actively used unless some custom monitoring takes advantage of it.
By addressing these issues, one can achieve a stable and robust LoadBalancer setup. The combination of MetalLB (for IP management) and Calico (for BGP route distribution) provides an elegant, cloud-native way to expose services in bare-metal clusters, with the networking intelligence handled at the routing layer.
This setup is suitable for advanced Kubernetes deployments where administrators have control over the network infrastructure and need to maximize performance and resilience for service exposure. With proper validation and monitoring, it can run in production to deliver cloud-like LoadBalancer services on premises.