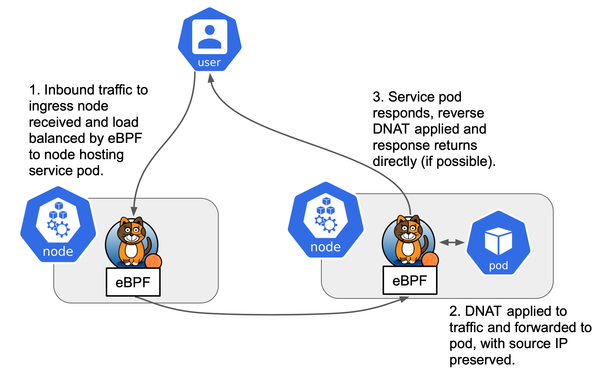
Analyzing Load Balancer VIP Routing with Calico BGP and MetalLB
MetalLB (controller-only) with Calico BGP does not bind VIPs to any node interface, causing ARP failures. Services stay unreachable externally. Solution: locally bind VIPs, enable strictARP, and disable rp_filter to restore correct traffic flow.

Abstract
In a bare-metal Kubernetes cluster using Calico in BGP mode (with MetalLB’s controller only), services of type LoadBalancer rely on Calico to advertise the VIPs. We examine why a service’s VIP becomes reachable internally under externalTrafficPolicy: Local but remains unreachable from the external routers, and why in Cluster mode the VIP is unreachable from both inside and outside.
The key issues are that no node ever binds the VIP to its interface, so ARP requests for the VIP go unanswered, and IPVS forwarding rules (and Linux reverse-path filters) do not handle this asymmetry by default.
We analyze how Calico’s BGP advertisements and kube-proxy/IPVS behavior interact in each mode. Finally, we outline architectural remedies: ensuring the VIP is bound on a host interface (so that ARP can resolve the IP), and adjusting Calico BGP and kube-proxy settings (such as enabling strictARP and disabling rp_filter) to restore proper traffic flow.
Background: Calico BGP for LoadBalancer IPs
Calico (v3.18+) can advertise Kubernetes Service LoadBalancer IPs via BGP without MetalLB speakers. In this setup, a Calico BGPConfiguration CRD includes the service VIP CIDR in serviceLoadBalancerIPs, and Calico’s bird daemons advertise routes for those addresses. The MetalLB controller still assigns IPs to Services, but the actual advertisement to routers is done by Calico.
By default Calico will advertise the entire CIDR block provided, so the upstream routers learn, e.g., 10.208.1.0/24 as reachable via the Calico nodes. Crucially, unlike MetalLB’s speakers, Calico does not bind the advertised VIP to a host network interface or answer ARP for it – it only installs routes. Kube-proxy in IPVS mode then creates a virtual IP rule for the VIP on each node (subject to externalTrafficPolicy). This combination means that packets destined for the VIP will be routed by the network to a Calico node, but whether they ever reach the service pods depends on how the Linux IPVS and ARP settings are configured.
externalTrafficPolicy: Local (Service Local)
With externalTrafficPolicy: Local, only nodes hosting a backend pod advertise (and accept) the VIP, preserving client source IP. Internally, pods in the cluster can reach the VIP (via kube-proxy IPVS on nodes with endpoints), so intra-cluster traffic appears normal.
However, external routers (the ToR switches) cannot reach the VIP. The BGP route (e.g. 10.208.1.1/32) will deliver packets to one of the Calico nodes, but no host interface has the VIP assigned, so the node never responds to ARP or accepts the packet. In a typical load‑balancer setup, one machine would bind the VIP to its NIC and broadcast a Gratuitous ARP so that switches learn the IP→MAC mapping. Here, without such binding, ARP requests for the VIP go unanswered and the IP remains “orphaned” on the network. In short, the cluster’s control plane and kube-proxy may be configured correctly, but at L2 the VIP is invisible. (This is evident if one uses arping on the VIP from another host: no replies will ever come, since no node claims that IP)
Additionally, Linux reverse-path filtering can drop the packet when it arrives (an asymmetric route). By default rp_filter is strict, so a packet coming in on an interface where the route to its source would go out via a different interface is discarded. In practice, setting net.ipv4.conf.all.rp_filter=0 (loose mode) is recommended to avoid dropping these replies and allow asymmetric ingress for LoadBalancer IPs. Disabling rp_filter (or setting it to “loose”/2) ensures the node does not reject the external packet simply because it didn’t originate on the same interface.
externalTrafficPolicy: Cluster (Service Cluster)
When the service uses externalTrafficPolicy: Cluster, kube-proxy configures the VIP on all nodes (cluster-wide VIP) and does SNAT, and Calico advertises the entire service CIDR (e.g. /24) as a single route. In theory, any node can receive the traffic and IPVS will load-balance it. However, in this case no node has the VIP on an interface, so the IPVS virtual address is never actually present at L2 on any host. Internally, pods cannot reach the VIP either, because the IPVS/iptables rules expect the VIP to be locally assigned. As a result, traffic to the VIP simply drops. In summary, without explicit binding, the network layer has no way to deliver or answer on the VIP in either mode: with Cluster, no node answers ARP or runs the VIP’s IP stack, and with Local, only nodes with backends do but still without binding. (By contrast, if the VIP were properly bound, Cluster mode would load-balance across all nodes, and Local mode would limit paths to the local endpoints.)
The Calico documentation’s service-advertisement table highlights this behavior: in Local mode only nodes with endpoints advertise the VIP (as a /32), whereas in Cluster mode all nodes advertise the broader service IP range. Here the broad advertisement still reaches the ToR, but since the VIP is “ghosted” (no physical presence), neither downstream router nor Kube-proxy can complete the path.
Root-Cause Analysis
- No VIP bound to a host interface. Calico in BGP mode does not configure the service IP on any Linux interface; it merely advertises a route. Thus, ARP (Layer 2) has no entry. Without a MAC for the VIP, upstream switches or routers cannot deliver packets – essentially the VIP is unroutable at L2.
- Missing ARP replies. Because no node claims the IP, ARP requests flood unanswered. (In MetalLB’s L2 mode, a speaker would respond, but here we rely solely on BGP. Even though routers route to the nodes, the final hop still uses ARP on the access link; no host responds.) As the kube-vip documentation notes, a VIP must be assumed by a node and bound to an interface to broadcast its IP→MAC mapping.
- Kube-proxy IPVS and strict ARP. In IPVS mode, the kube-proxy (when strictARP is disabled) can cause all nodes to attempt answering ARP for cluster IPs, leading to conflicts. MetalLB’s docs explicitly instruct enabling
strictARP: trueso that only the correct node replies to ARP for a service IP. In our case, because no node has the IP, even strictARP won’t produce an answer – but enabling strictARP is still important for consistent behavior once the IP is bound. - Reverse-path filtering (rp_filter). The default Linux setting may drop inbound packets whose source routes out differently. In LoadBalancer scenarios with BGP, packets may arrive on an interface that is not on the expected return path. Disabling rp_filter (setting it to loose mode or 0) avoids this asymmetric-drop. In fact, the user observed that setting
rp_filter=0on nodes allowed the service to work, confirming that rp_filter was rejecting valid traffic due to asymmetric routing.
Architectural Recommendations
- Bind the VIP to nodes (ARP announcement). The fundamental fix is to ensure the VIP is actually configured on a node interface so that ARP and IPVS can work. This can be done by running a simple daemon (or using a project like kube-vip or keepalived) that watches the Service and binds its VIP to a host NIC (and optionally sends a gratuitous ARP) when needed. With the VIP on the interface, the ToR’s ARP requests will be answered and Linux will accept packets for that IP. In a Calico setup, one could elect one or more nodes as VIP owners (for HA, use layer-2 failover) while Calico continues to advertise the route.
- Adjust Calico BGP settings. Ensure the Calico BGPConfiguration includes the correct LB CIDR in
serviceLoadBalancerIPsso only the intended range is advertised. (Calico will advertise the whole block; if you want more specific /32 routes, list them explicitly.) Also consider whether you need to advertise the Service’s ClusterIP range or ExternalIPs via Calico; advertising the ClusterIP CIDR can make internal addressing more robust if needed. In multi-rack deployments, follow MetalLB’s guidance on BGP peering: if Calico consumes the node–ToR session, you can peer MetalLB with a spine router or dedicate racks to external services. - Enable kube-proxy strictARP. If using IPVS, edit the kube-proxy ConfigMap to set
mode: "ipvs"andipvs.strictARP: true. This ensures that only the node with the bound VIP will answer ARP (once configured), avoiding ARP “storms” and ensuring correct MAC ownership. Strict ARP is recommended by MetalLB documentation for exactly this reason. - Disable rp_filter. On each node, set
net.ipv4.conf.all.rp_filter=0(and similarly fordefaultor any bridged interface). This allows replies even if the traffic appears asymmetric, which is common in BGP-advertised LoadBalancer scenarios. (It was verified in practice that disabling rp_filter let the asymmetric return traffic flow.) - Service policy choice. Generally, use
externalTrafficPolicy: Localif you need to preserve source IP and if you can bind the VIP to local nodes. Note that Local mode can result in uneven load if endpoint counts differ per node. UsingClustermode would require correct SNAT and may need additional ECMP support on the ToR (Calico advertises the whole CIDR and upstream routers can load-balance among nodes). Ensure your network supports ECMP on the service subnet if using Cluster mode.