Web 后端应用程序的可观测性改进


相信日志,即 Logging,对于大多数开发人员是不陌生的。
日志是一种记录应用程序运行状态的重要手段,它可以帮助我们了解应用程序的运行情况,排查问题,甚至是监控应用程序的性能。在 Web 后端应用程序中,日志是不可或缺的一部分,它可以记录用户请求、应用程序的错误、警告等信息,帮助我们更好地了解应用程序的运行情况。
但它真的不可或缺吗?读完这篇文章后我想我给你的答案是:不是。日志的形式很单一,只是文本,这注定了它很冗杂的特点,我们很难从中提取我们需要的信息。即使你使用 AI 如 ChatGPT,也并不一定可以得到一个有建设性的答案。对于自己构建的应用程序,ChatGPT 既不了解也不可能去真的全部了解你的代码,这就带来了问题。
为什么日志不是不可或缺的
日志的形式单一,以纯文本呈现,信息常常显得冗余且难以提取。即便是使用 AI 进行分析,也不一定能提供清晰的洞见。日志的主要问题在于:
- 冗余性和庞大的数据量:日志往往包含大量无用信息,查找特定问题的关键信息耗时。
- 缺乏上下文关联:单条日志难以呈现多个服务之间的调用关系和上下文,尤其是在微服务架构中。
- 实时性不足:仅依赖日志,难以及时洞察性能问题和实时状态。
举个例子,假设你在调试时遇到以下日志:
@ahdark-blog/web:dev: GET /category/Backend-Development 500 in 8714ms
@ahdark-blog/web:dev: ⨯ dist/compiled/react-server-dom-webpack/cjs/react-server-dom-webpack-server.edge.development.js (2105:18) @ stringify
@ahdark-blog/web:dev: ⨯ TypeError: Converting circular structure to JSON
@ahdark-blog/web:dev: --> starting at object with constructor '_Document'
@ahdark-blog/web:dev: | property 'tags' -> object with constructor '_Query'
@ahdark-blog/web:dev: | property 'data' -> object with constructor 'Array'
@ahdark-blog/web:dev: | ...
@ahdark-blog/web:dev: | property 'data' -> object with constructor 'Array'
@ahdark-blog/web:dev: --- index 0 closes the circle
@ahdark-blog/web:dev: at stringify (<anonymous>)
@ahdark-blog/web:dev: at stringify (<anonymous>)
@ahdark-blog/web:dev: digest: "14907588"
@ahdark-blog/web:dev: 2103 | function outlineConsoleValue(request, counter, model) {
@ahdark-blog/web:dev: 2104 | "object" === typeof model && null !== model && doNotLimit.add(model);
@ahdark-blog/web:dev: > 2105 | var json = stringify(model, function (parentPropertyName, value) {
@ahdark-blog/web:dev: | ^
@ahdark-blog/web:dev: 2106 | try {
@ahdark-blog/web:dev: 2107 | return renderConsoleValue(
@ahdark-blog/web:dev: 2108 | request,
@ahdark-blog/web:dev: ⨯ dist/compiled/react-server-dom-webpack/cjs/react-server-dom-webpack-server.edge.development.js (2105:18) @ stringify
@ahdark-blog/web:dev: ⨯ TypeError: Converting circular structure to JSON
@ahdark-blog/web:dev: --> starting at object with constructor '_Document'
@ahdark-blog/web:dev: | property 'tags' -> object with constructor '_Query'
@ahdark-blog/web:dev: | property 'data' -> object with constructor 'Array'
@ahdark-blog/web:dev: | ...
@ahdark-blog/web:dev: | property 'data' -> object with constructor 'Array'
@ahdark-blog/web:dev: --- index 0 closes the circle
@ahdark-blog/web:dev: at stringify (<anonymous>)
@ahdark-blog/web:dev: at stringify (<anonymous>)
@ahdark-blog/web:dev: digest: "14907588"
@ahdark-blog/web:dev: 2103 | function outlineConsoleValue(request, counter, model) {
@ahdark-blog/web:dev: 2104 | "object" === typeof model && null !== model && doNotLimit.add(model);
@ahdark-blog/web:dev: > 2105 | var json = stringify(model, function (parentPropertyName, value) {
@ahdark-blog/web:dev: | ^
@ahdark-blog/web:dev: 2106 | try {
@ahdark-blog/web:dev: 2107 | return renderConsoleValue(
@ahdark-blog/web:dev: 2108 | request,
因为这个问题,我放弃了 Next.js 重构的前端,转而使用 xLog。
从日志中我们可以得知 JSON.stringify 无法处理循环引用,但日志并未告诉我们 为什么 出现这一问题、如何产生以及如何避免。当然你也可以通过堆栈处理,但堆栈复杂,且在很多场景下抛出错误的地方可能并不是实际错误的地方。这就引出我们需要更多的可观测性(Observability)。
什么是可观测性
可观测性是指我们可以通过指标(Metrics)、日志(Logging)、追踪(Tracing)等手段来监控和调试应用程序的能力。可观测性是非常重要的,它可以帮助我们更好地了解应用程序的运行情况,排查问题,甚至是协助监控应用程序的性能。在先前的互联网应用程序中,日志被作为最主要的提高可观测性的手段。但在当下,大厂更倾向于使用大规模分布式追踪系统,以 Tracing 和 Metrics 为主,日志为辅,对应用程序进行全链路的追踪。
即,当下的可观测性改进主要趋于整体化、全链路化,而不是单一的分散的日志记录。这种变革的背景主要在于微服务系统盛行以及软件规模的扩展。大厂的软件系统往往由数千个服务组成。在这种规模下,单一的日志记录不够连续,不能够精确定位问题。因此需要更多的追踪和指标来帮助业务系统进行监控排障、链路梳理、性能分析。
我们首先简单概括一下可观测性的三个主要组成部分:
- 日志(Logging):提供事件信息,主要用于细粒度问题排查,但会产生大量数据,难以全面捕捉系统行为。
- 指标(Metrics):在宏观上展示系统性能及趋势,便于进行实时监控和预警。
- 追踪(Tracing):细粒度地记录请求的完整路径,特别适合微服务架构,能够跨服务跟踪请求,精确定位延迟和故障。
Tracing
Tracing 是指我们可以追踪应用程序的每一个请求的处理过程,从而了解应用程序的运行情况。在 Web 后端应用程序中,Tracing 可以帮助我们知道如一个请求消耗了多少时间等信息,也可以更好地联系函数调用、服务调用的上下文(Context)关系。
Tracing 的实现主要依赖于分布式追踪系统,其就如一种标准化、结构化的 Log,提供更全面、更连续、更完善的信息,并且运行在统一的平台。这使开发者不需要去每一个服务找对应的文本日志信息(以目前大厂规模,这也不太可能),而是可以在一个平台上查看所有服务的日志信息,如 Jaeger、Zipkin 等。
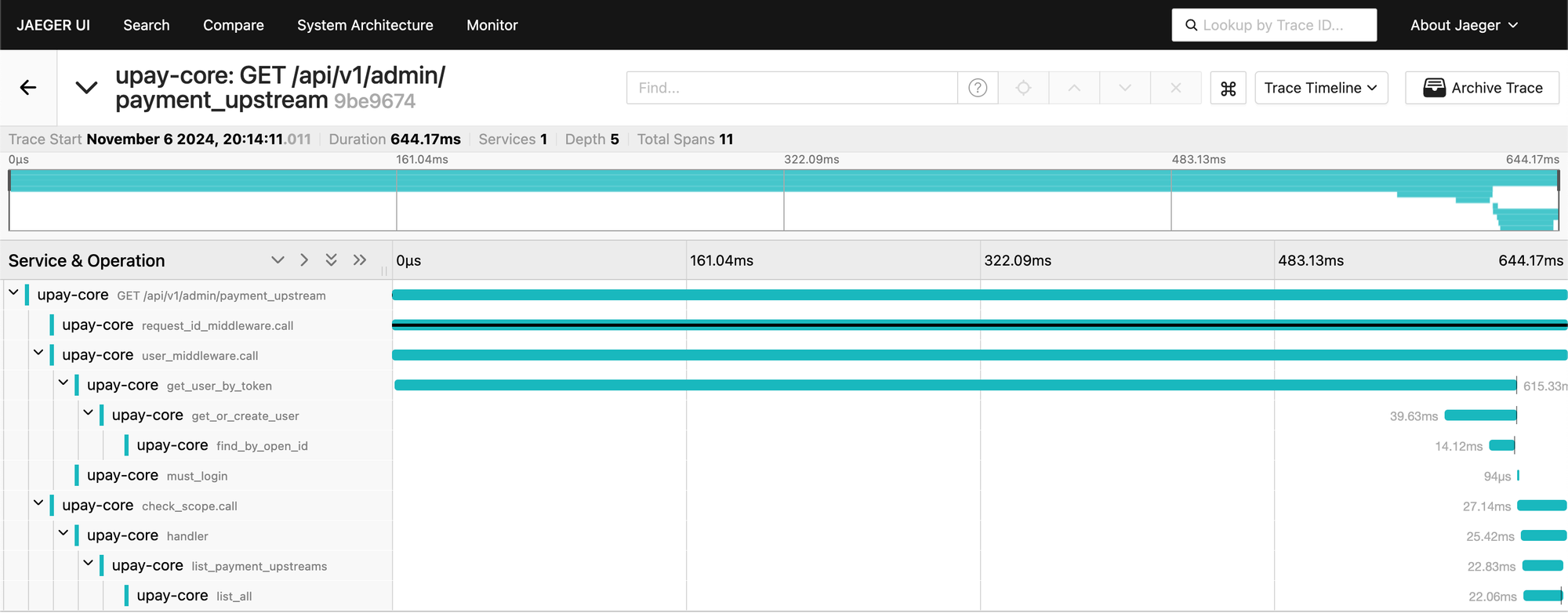
得益于 Tracing 标准提供的丰富的数据,当我们对某个 Metric 波动发生兴趣时,可以直接将造成此波动的 Trace 关联检索出来,然后查看这些 Trace 在各个微服务中的所有执行细节,发现是底层某个微服务在执行请求过程中发生了 Panic,这个错误不断向上传播导致了服务对外 SLA 下降。
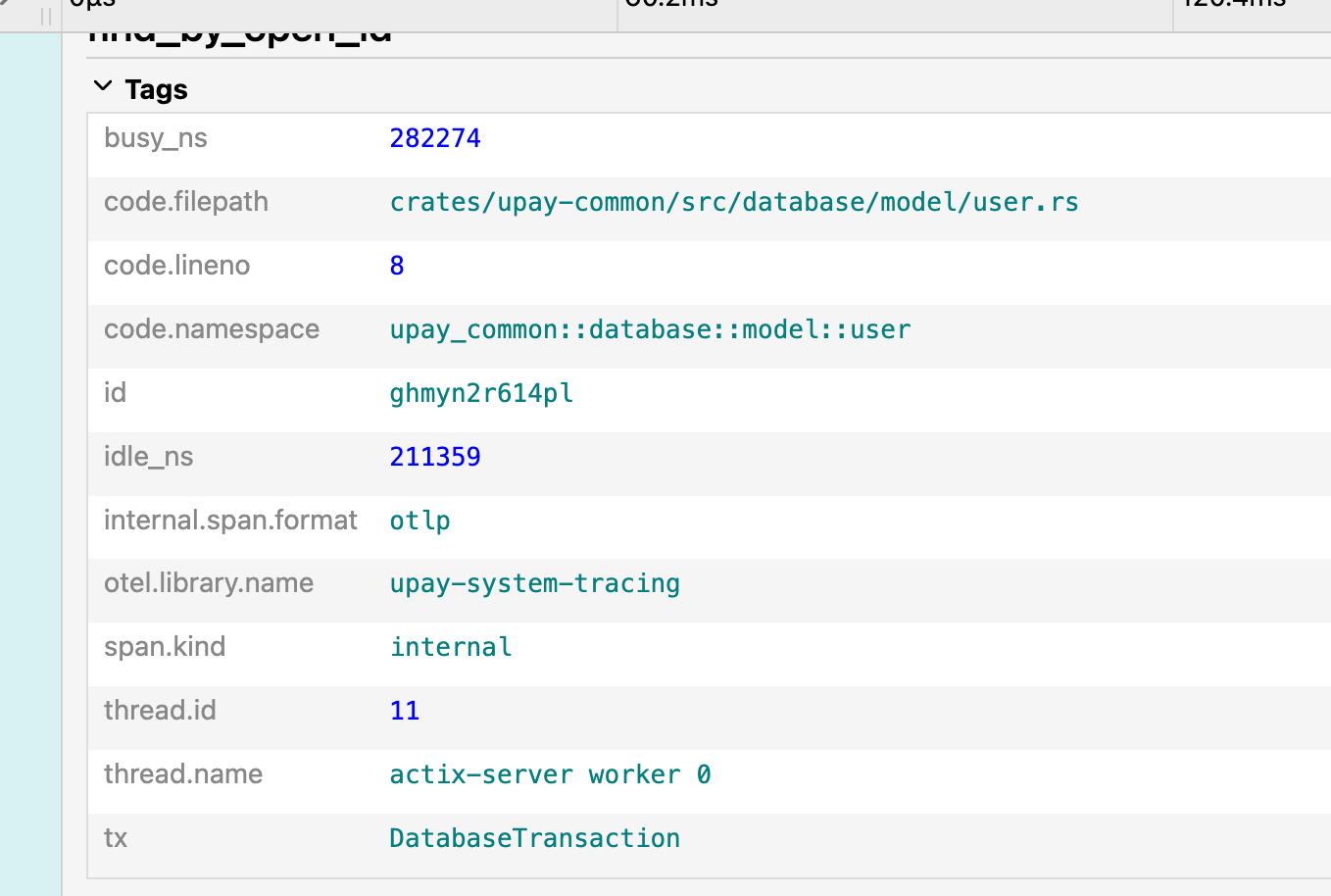
Trace 的采集和跨服务进程的 Context 传递通常由微服务框架等基础设施自动处理,但要达到最佳效果,仍需要所有开发人员的理解和配合。
开发人员在编码时应主动在所有代码执行过程中保持 Context 的传递。例如,在 Golang 中,context.Context 需要在所有函数调用中作为参数连续传递;而在 Java 中,通常使用 ThreadLocal 作为 Context 的存储载体,但在多线程或异步场景下,开发者需手动显式传递 Context,否则上下文可能中断,无法实现有效的追踪和监控;Rust 的 Open Telemetry 基于 Tokio Tracing 库使用,使用线程内变量传递 Context,但在 async 调用也需要单独的 instrument 函数调用来注入 Span 进行传递。
Metrics
Metrics 是指我们可以通过指标来监控应用程序的性能,如 CPU 使用率、内存使用率、磁盘使用率等。Metrics 可以帮助我们监测性能数据、业务数据等,有助于宏观上了解应用程序的运行情况。相对于 Tracing 对于每一条请求的细致记录,Metrics 更多的是对于整体性能的监控。Metrics 包括 Counter、Gauge、Histogram、Summary 等,他们大多只是单一的数值,但在大规模数据下可以快速检测应用程序的运行情况。比如 SLA 的数据下降可以快速定位到某一个服务、函数调用,从而快速定位问题。
Metrics 的实现主要依赖于监控系统,如 Prometheus、Grafana 等。Metrics 更像是一种应用程序内的数据分析,相比于 Log 具有更宏观的特点,但相应的其需要大量数据作为支撑,因此在小规模应用程序中,Metrics 的作用并不是很大。
常见的 Metrics 场景包括 CPU 使用率、内存使用率、磁盘使用率、网络流量等,这些数据通常由 node_exporter、cAdvisor 等监控系统采集,然后通过 Prometheus 等监控系统进行存储和展示。在应用程序中,我们可以记录一些自定义的 Metrics,如请求处理时间、请求成功率等,这些数据可以帮助我们更好地制定优化策略。
代码中可观测性提高的具体实现
在代码中,我们可以通过引入一些库来提高可观测性,当下最常用的库是 Open Telemetry[1]。Open Telemetry 是一个开源的分布式追踪系统,它提供了一套标准化的 API,可以帮助我们更好地追踪应用程序的运行情况。OpenTelemetry 支持多种语言,如 Golang、Java、Python、Rust 等,可以帮助我们更好地追踪应用程序的运行情况。
在本篇文章,我们主要介绍 Open Telemetry 在 Rust 中的使用。我不在此过多赘述 Open Telemetry 的核心概念,你可以查看官方文档来了解更多:OpenTelemetry Concepts 我只在此简述几个级别概念。
- Span:Span 是 Open Telemetry 中的基本单位,它代表了一个操作的执行时间。Span 通常包括一个开始时间、一个结束时间、一个操作名、一些属性等信息。Span 可以嵌套,形成一个树状结构,用于表示一个操作的执行过程。
- Trace:Trace 是一组 Span 的集合,它代表了一个操作的整个执行过程。Trace 通常包括一个 Trace ID、一个 Span ID、一些属性等信息。Trace 可以用于表示一个操作的整个执行过程。
- Context:Context 是 Open Telemetry 中的上下文,它用于传递 Span 和 Trace 信息。Context 通常包括一个 Trace ID、一个 Span ID、一些属性等信息。Context 可以用于传递 Span 和 Trace 信息,你可以通过 Propagator 来序列化并传递 Context。需要注意的是,对于 remote 传入的已经被记录的 context,你需要使用单独的构建方法。
配合使用 tracing 和 opentelemetry
tracing 是 Rust 中的一个追踪库,由开山祖师 Tokio 提供。tracing 提供了一套更符合 Rust 设计哲学的方式进行追踪,相比于 Go 的 context.Context,它更优雅。同时,利用 Rust 的过程宏和零成本抽象,提供了更好的性能。想要为函数加上追踪,只需要在函数前加上 #[tracing::instrument] 即可。
#[tracing::instrument]
fn my_function() {
// do something
}
// Only record on debug level
#[tracing::instrument(level = tracing::Level::DEBUG)]
fn inner_function() {
// do something
}
// Automatically record error and return value
#[tracing::instrument(ret, err)]
async fn function_with_data() -> Result<String, Box<dyn std::error::Error>> {
"Hello, world!".to_string()
}
// Automatically record error
#[tracing::instrument(err)]
async fn function_with_error() -> Result<(), Box<dyn std::error::Error>> {
// do something
}
将 tracing 和 opentelemetry 结合使用,可以更好地追踪应用程序的运行情况。tracing 提供了更好的追踪方式,而 opentelemetry 提供了更好的追踪数据的存储和展示。
pub fn init_tracer(config: &ObservabilityConfig, resource: Resource) {
let exporter = HttpExporterBuilder::default().with_endpoint(config.endpoint.clone().expect("OTEL_EXPORTER_ENDPOINT not set"));
let provider = opentelemetry_sdk::trace::TracerProvider::builder().with_config(
opentelemetry_sdk::trace::Config::default()
.with_sampler(Sampler::TraceIdRatioBased(config.sample_rate.unwrap_or(1.0)))
.with_resource(resource)
)
.with_batch_exporter(
exporter.build_span_exporter().expect("Failed to build exporter"),
opentelemetry_sdk::runtime::Tokio,
)
.build();
global::set_text_map_propagator(TraceContextPropagator::new());
let telemetry = tracing_opentelemetry::layer().with_tracer(provider.tracer("system-tracing"));
let env_filter = EnvFilter::try_from_default_env().unwrap_or(EnvFilter::new("INFO"));
let subscriber = Registry::default()
.with(telemetry)
.with(env_filter)
.with(tracing_subscriber::fmt::layer());
tracing::subscriber::set_global_default(subscriber)
.expect("Failed to install `tracing` subscriber.");
global::set_tracer_provider(provider);
}
这段代码初始化了 Trace Provider,通过中间件将其转化为 Tokio Tracing 的 Layer 和 Subscriber,并将其设置为全局默认的 Tracer Provider。值得注意的是,我们并不会使用 opentelemetry::Context::current() 中存储的线程 Context(这个数据甚至不存在),而是在最终提交数据的时候把 Tokio Tracing Span 转化为 Open Telemetry Span。这是 lib 自动完成的。
一个问题是,由于 Tracing 要求 Span 的名字必须是静态的(&'static str),这从根本上禁止了动态 Span 名字。这在某些场景下是不可接受的,比如在一个 HTTP 服务中,我们可能需要根据请求的 URL 动态生成 Span 名字。这时我们可以使用 attributes 中 otel.name 来指定 Span 名字。相应的也有一些其它可用的 attributes,如 otel.status_code 等。
otel.name:Span Nameotel.status_code:Span Status Codeotel.kind:Span Kind,包括client、server、producer、consumer、internal等.
比如我这样构建 volo 的 Tracing 中间件:
#[volo::service]
impl<Cx, ReqBody, ResBody, ResErr, S> Service<Cx, Request<ReqBody>> for InnerTracingExtractLayer<S> {
async fn call(&self, cx: &mut Cx, req: Request<ReqBody>) -> Result<S::Response, S::Error> {
let method = cx.rpc_info().method().as_str();
let span = tracing::span!(
tracing::Level::INFO,
"rpc_call",
rpc.method = method,
otel.name = format!("RPC {}", method),
otel.kind = "server",
);
// ...
}
}
在 Actix 等框架中使用
Web Server 天生适合使用 Tracing,因为它们具有线性的 Context。在 Actix 中,我们可以使用 tracing-actix-web[2] 来集成 Tracing。
use actix_web::{App, web, HttpServer};
use tracing_actix_web::TracingLogger;
fn main() {
// Init your `tracing` subscriber here!
let server = HttpServer::new(|| {
App::new()
// Mount `TracingLogger` as a middleware
.wrap(TracingLogger::default())
.service( /* */ )
});
}
诸如此类,其它框架也有类似的中间件,你可以自行查找。由于 Open Telemetry 是绝大多数企业的主流追踪系统,因此框架往往都会提供相关支持,如:https://www.cloudwego.io/docs/hertz/tutorials/observability/open-telemetry/
Remote Span 的传递
在分布式系统中,我们通常需要将 Span 传递到远程服务。Open Telemetry 提供了一套标准化的 Context 传递机制。但在 Rust 中,面对结合了 tracing 的复杂 Context 传递,我们需要额外的处理。
if let (Some(trace_id), Some(span_id)) = (
req.metadata().get("trace_id").and_then(|s| s.to_str().ok()),
req.metadata().get("span_id").and_then(|s| s.to_str().ok()),
) {
let cx = opentelemetry::Context::new().with_remote_span_context(SpanContext::new(
TraceId::from_hex(trace_id).unwrap(),
SpanId::from_hex(span_id).unwrap(),
Default::default(),
true,
Default::default(),
));
span.set_parent(cx);
}
这里边存在一些细节:
- 我们通过
with_remote_span_context方法创建了一个 Remote Span Context。不同于创建普通的 Span Context,Remote Span Context 不会被提交到本地的 Tracer,而是在最终提交的时候被转化为 Remote Span。如果你试图传递 Tokio Tracing 的 Span ID,由于这个 Span 来自外部,本地会因为找不到这个 Span 而报错。 - 我们调用了
opentelemetry::trace::TraceContextExt中为tracing的Span提供的set_parent方法。这个方法会将tracing的 Span 和opentelemetry的 Span 进行关联,从而实现远程 Span 的传递。你可以看出,我们初始化的 Context 是opentelemetry的 Context,而不是tracing的 Context。这是因为tracing的 Context 无法基于 Remote 数据进行序列化,并且我们传递的数据也是基于opentelemetry的 Span Context。
你可以看出一个问题,Open Telemetry 虽然对每个语言的适配不是那么完美,但重在跨语言、跨服务的标准化处理。而 Rust 的 tracing 虽然更加注重于 Rust 的设计哲学、提供了更好的性能和更好的使用体验,但相应的,它完全无法跨服务使用。这就是我们需要结合 Open Telemetry 和 Tracing 的原因,即使我所撰写的微服务系统完全由 Rust 编写。
Async 传递中 instrument 的使用
在 Rust 中,我们通常使用 tokio::spawn 来开启一个异步任务。但在异步任务中,我们无法直接基于线程 Context 来为函数加上追踪。因为异步任务的生命周期是不确定的,它大概率不在当前线程中执行。因此,我们需要在异步任务中手动为函数加上追踪的信息。
比如当构建 Actix Middleware 时,我们通过 tracing::Instrument trait 提供的 instrument 函数为 Async 加上追踪信息:
impl<S, B> Service<ServiceRequest> for UserMiddlewareService<S>
where
S: Service<ServiceRequest, Response=ServiceResponse<B>, Error=actix_web::Error> + 'static,
S::Future: 'static,
B: 'static,
{
fn call(&self, req: ServiceRequest) -> Self::Future {
let parent_span: Span = req.extensions().get::<RootSpan>().map(|s| s.clone().into()).unwrap_or(Span::none());
let span = tracing::info_span!(parent: parent_span, "user_middleware.call");
let _enter = span.enter(); // Enter the span
// some actions...
drop(_enter); // Exit the span
async move {
// some actions...
service.call(req).await
}
.instrument(span)
.boxed_local()
}
}
这里我们通过 tracing::info_span! 创建了一个 Span,然后通过 instrument 函数为异步任务注入了当前的 Span 作为 parent 进行进一步追踪。
总结
可观测性是一个非常重要的概念,它可以帮助我们更好地了解应用程序的运行情况,排查问题,甚至是监控应用程序的性能。我从 2022 年开始在 Go 程序使用链路追踪。我本人极度注重链路追踪,不仅在于其细致内容对于工作效率的提高,链路追踪还能够提高系统的完备性、稳定性。在我看来,链路追踪是现代应用程序的一个重要标志。任何规模化的应用程序都无法脱离链路追踪,尤其在大厂,往往一整套容灾方案都在于链路追踪的一个 Metrics。我们应该更加重视可观测性,通过引入一些方法来完善应用程序,以此提高问题定位的精确度和效率。
本文提供的方法和示例代码可以帮助你在实际项目中实现更高效的监控和排障。
tracing-actix-web 是一个民间维护的 Actix Web Tracing 中间件。 ↩︎